



| 最恐怖的來了:我看不懂,嘿嘿! |
| 送交者: 花蜜蜂 2019年11月27日11:09:48 於 [天下論壇] 發送悄悄話 |
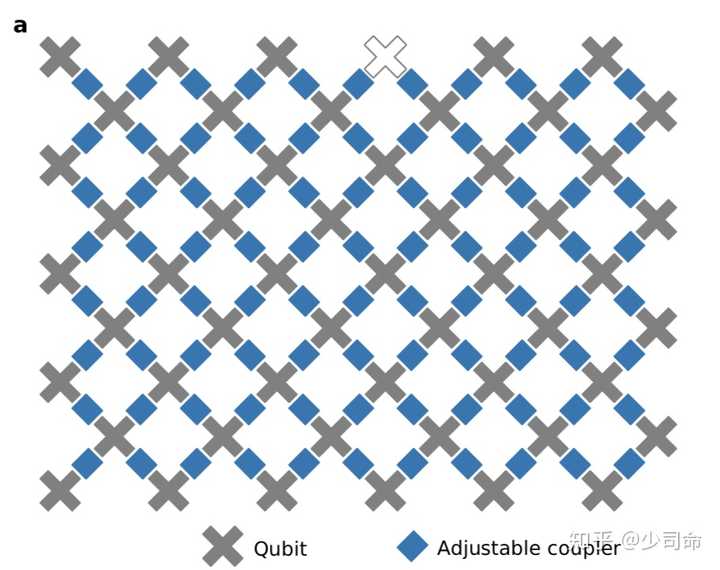
如何評價 Google 宣稱率先實現量子霸權?前沿資訊 ⋅ 你找不到我 ⋅ 於 2個月前 ⋅ 1086 閱讀 作者:少司命 9月20號剛剛看到這個消息,據說是NASA發布到官網上而後又迅速刪掉,但是內容已經在網上大規模流傳開了。文章《Quantum supremacy using a programmable superconducting processor》寫的非常簡單易懂,我儘量用簡單的語言陳述一下這個新聞的主要內容吧(蹭熱度),如果沒有任何背景可以只看加粗字體部分。如果哪裡不準確歡迎指正補充。 首先一個概念,所謂的quantum supremacy,有人翻譯為量子優勢也有人翻譯為量子霸權,一般指的是量子計算在某一個問題上,可以解決經典計算機不能解決的問題或者是比經典計算機有顯著的加速(一般是指數加速)。 回到文章,在硬件方面,谷歌家一直用的是超導電路系統,這裡是54個物理比特(transmon)排成陣列,每個比特可以與臨近的四個比特耦合在一起,耦合強度可調(從0到大概40MHz),實物圖和示意圖分別如下。
▲From[1]. Google54比特名為Sycamore的芯片,中文應該叫做"楓樹"?
▲From[1]. 圖中一個灰色的叉號就代表一個量子比特,藍色的則是可調的耦合裝置 有了硬件就要衡量其性能的好壞,所以首先要知道對這些量子比特進行操作時發生錯誤的概率(error rates)。這裡他們用cross-entropy benchmarking (XEB)的方法測量這些error。XEB早就有了我記得google在今年3月會議時候就講過,跟randomized bechmarking很像都是加一系列隨機的門操作,然後從保真度衰減信號中提取出error rates. 下圖是他們最終得到的結果,在沒有並行時候單比特0.15%的錯誤率其實不算高,而雙比特0.36%的錯誤率e2有0.36%則還不錯,像google另一個18比特的Gmon18我記得兩比特的有0.8%.
下面是文章最重要的部分,google在多項式時間內實現了對一個隨機量子電路的採樣,而在已知的經典計算機上需要的時間則非常非常之久,像文中實現的最極端的例子是,對一個53比特20個cycle的電路採樣一百萬次,在量子計算機上需要200秒,而用目前人類最強的經典的超級計算機同樣情況下則需要一萬年。亦即在這個問題上,量子實現了對經典的超越。這裡的cycle指的是對這些比特做操作的數目,一個cycle包含一系列單比特操作和雙比特操作,可以近似理解為電路的深度(circuit depth)。 對於最大的電路,即53個比特20個cycle的情況,在量子處理器上做一百萬次採樣後得到XEB保真度大於0.1% (5倍置信度),用時大概200秒. 而要在經典計算機上模擬的話,因為比特數目很多整個的希爾伯特空間有 而且還有那麼多電路操作,這已經超出了我們現在超級計算機的能力(within considerable time),就像文中舉的另一個例子,用SFA算法大概需要50萬億core-hour(大概是一個16核處理器運行幾億年吧), 加 kWh的能量(也就是一萬億度電...),可以想見是多麼難的事情了。而量子這個問題上為啥會比經典好也非常容易理解,用到的就是量子運算的並行性,即量子態可以是疊加態可以在多項式時間內遍歷整個希爾伯特空間,而經典計算機模擬的話需要的資源則是隨着比特數目指數增加的。
當然有沒有可能是有些更好的經典採樣算法和量子的差不多,只是我們沒有找到呢?文中沒有給出很直接的回答,他們認為從複雜度分析來講經典算法總是會隨着比特數和cycle指數增加的,而且即使未來有一些更好的經典算法,到時候量子的處理器也發展了所以還是會比經典的好。 算法上,除了這裡的採樣問題(由此延伸的可以解決的問題其實是非常有限的),又有哪些問題是可以證明量子比經典有顯著優勢的,可不可以設計一些算法使得量子計算機能解決經典不能解決的問題,或者量子比經典有顯著的加速,就像文章最後所說的:
在NISQ(noisy-intermediate scale quantum computer)的時代(如下圖),雖然我們離綠色真正的容錯通用量子計算機還很遠,但是現在已經開始進入到藍色區域相信在未來幾年會有一些有趣的near-term的應用出現。
回答一下大家關心的問題吧,以下是個人觀點 一個是中國在這方面有什麼進展,我們國家在近些年在量子方面投入很大,很多組也做出了許許多多非常突出的貢獻,但必須承認的是,至少在我們在文中提到的用超導比特去做通用量子計算機這方面確實還有着比較明顯的差距,但是道路是曲折的前途是光明的,我相信國內一定會迎頭趕上並在很多領域做出超越的。現在無論學校科研院所還是大企業都有投入和發力,只不過具體方向會不一樣很多優秀的成果也沒有得到媒體的關注。 再一個問題就是很多同學表示還是看不太懂,確實沒有相關背景了解起來會比較吃力,既準確又通俗的科普是件很難的事...anyway, 還是我在文中強調的,文章的內容是量子計算重要的一步但是其應用是非常非常有限的,以後的路仍道阻且長,我們離着可以破解RSA密碼離着量子計算機的大規模普及還很遠,而且量子計算機也是不可能取代現在用的經典計算機的,這些應該是現在的業內共識。 原文鏈接:https://www.zhihu.com/question/346999432/answer/830557113 |




|
|
 |
 |
| 實用資訊 | |
|
|
| 一周點擊熱帖 | 更多>> |
| 一周回復熱帖 |
| 歷史上的今天:回復熱帖 |
| 2018: | 七絕 題照(560)九州百姓盡昏昏 | |
| 2018: | 笑侃郭文貴的“發動全民找證據運動” | |
| 2017: | 徹底否定中國文化是正確的 | |
| 2017: | 改變自己即是改變中國 | |
| 2016: | 美式民主制度是迄今人類社會管理制度中 | |
| 2016: | 美國的民主制度沒有變化,他是剛性的 | |
| 2015: | 蘋果日報:俄集束彈炸難民營 波及土國 | |
| 2015: | 楊光:南海島礁爭端是中國的機遇還是陷 | |
| 2014: | "毛澤東讓高崗查劉少奇檔案"一說辨析 | |
| 2014: | 公孫明:老毛與老共國際派之間的鬥爭 | |
