



| 人工智能功能 |
| 送交者: mingcheng99 2025年06月18日21:35:03 于 [五 味 斋] 发送悄悄话 |
|
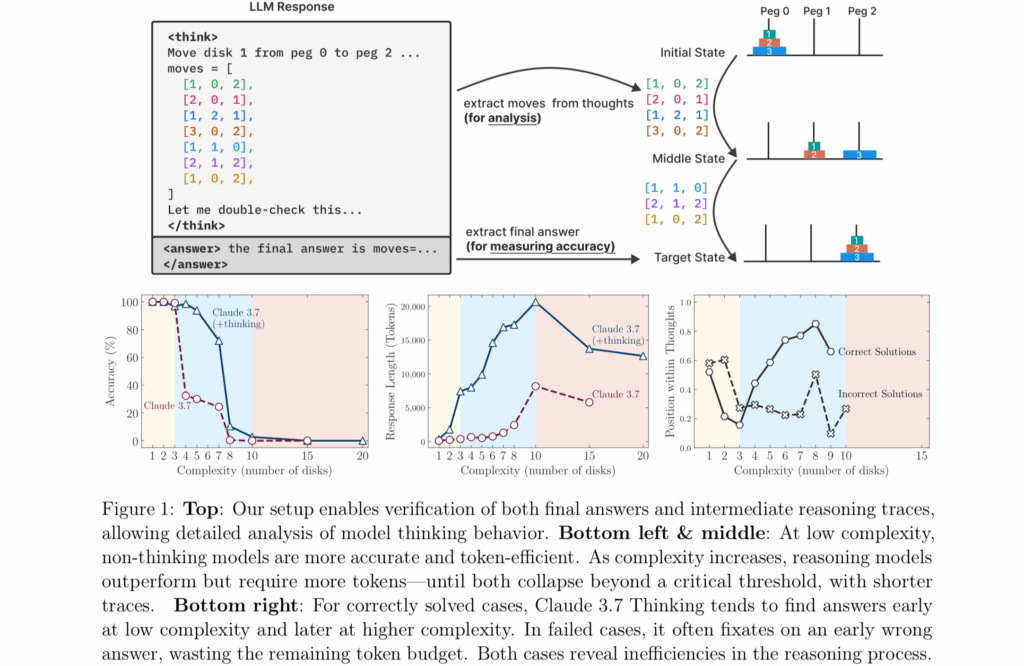
2025年6月初,苹果公司发布了一项引发广泛关注的研究,题为《思维的幻象:从问题复杂度视角理解推理模型的优势与局限》。研究指出,当前被称为“模拟推理模型(Simulated Reasoning Models, SR)”的AI系统——如OpenAI的o1与o3、DeepSeek-R1,以及Claude 3.7 Sonnet Thinking——在面对需要系统性思维的全新问题时,其输出更像是对训练数据中模式的匹配,而非真正的逻辑推理。 研究团队由Parshin Shojaee与Iman Mirzadeh领衔,成员还包括Keivan Alizadeh、Maxwell Horton、Samy Bengio 和 Mehrdad Farajtabar。他们将这些“大型推理模型(Large Reasoning Models, LRMs)”置于四种经典逻辑难题中进行测试:
这些问题从极易(如一片圆盘的汉诺塔)逐步升级到极难(如20片圆盘的汉诺塔,需超过百万步移动)。 研究发现,尽管这些模型在中等复杂度任务中表现尚可,但一旦问题复杂度上升,其表现会急剧下降甚至崩溃。即使研究人员在提示中提供了解题算法,模型也无法稳定执行逻辑步骤。这与2025年4月美国数学奥林匹克(USAMO)的一项研究结果一致:这些模型在面对全新数学证明题时得分极低,几乎没有模型能完成完整的逻辑推导。 这项研究不仅挑战了“AI是否真的在思考”的观念,也为未来构建真正具备推理能力的AI模型提供了重要参考。
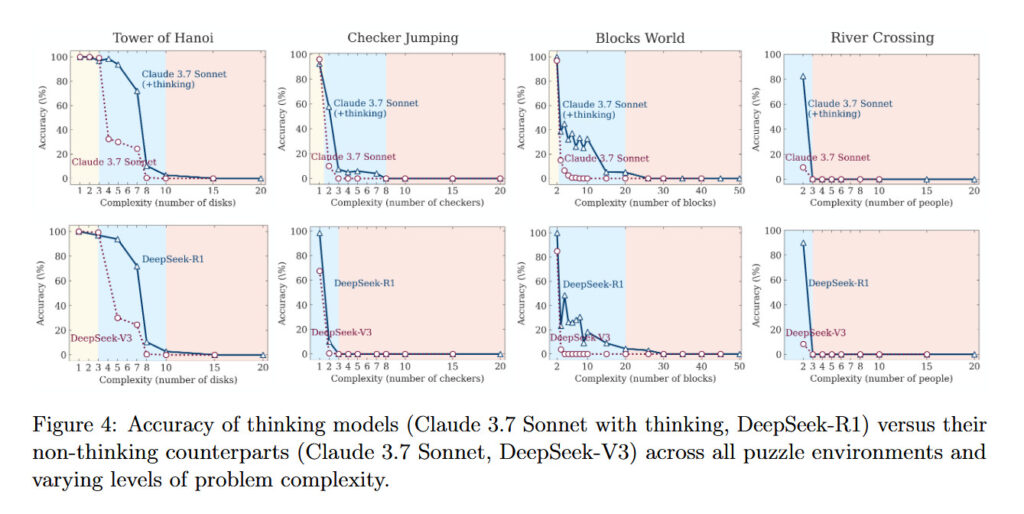
研究人员指出:“当前的评估主要集中在既定的数学和编程基准上,强调的是最终答案的准确性。”换句话说,如今的测试更关注模型是否给出了正确答案,而不是它是否通过真正的推理过程得出该答案——很可能只是从训练数据中模式匹配而来。 最终,这项研究的结果与美国数学奥林匹克(USAMO)在2025年4月发布的研究高度一致:这些AI模型在面对全新的数学证明题时,表现极差,大多数模型的正确率低于5%,只有一个模型达到了25%,而在近200次尝试中,没有一次成功完成完整的证明。 两项研究都记录了一个关键现象:当问题需要持续、系统性的推理时,模型的性能会严重下降。这表明,尽管这些AI系统在熟悉任务中表现出色,但在真正需要“思考”的新问题面前,它们仍然显得力不从心。 知名AI怀疑论者加里·马库斯(Gary Marcus)长期以来一直主张:神经网络在处理“分布外问题”(out-of-distribution generalization)时存在严重困难。在苹果公司最新发布的研究中,他称这些结果对大型语言模型(LLMs)来说是“相当毁灭性的”。 马库斯指出,即使研究人员为模型提供了解决汉诺塔问题(Tower of Hanoi)的明确算法,模型的表现依然没有改善。他写道:“LLMs 连汉诺塔都无法可靠解决,实在令人尴尬。”他还提到,早在1957年,AI先驱赫伯特·西蒙(Herb Simon)就已经成功解决了这个问题,而如今网络上也有大量现成的算法可供参考。 研究共同负责人伊曼·米尔扎德(Iman Mirzadeh)进一步指出,这一现象表明这些模型的“推理过程并不真正具备逻辑性和智能性”。 这项研究为马库斯多年来的批评提供了新的实证支持,也再次引发了关于AI是否真正“思考”的深层讨论。 Figure 4 from Apple's "The Illusion of Thinking" research paper. Credit: Apple
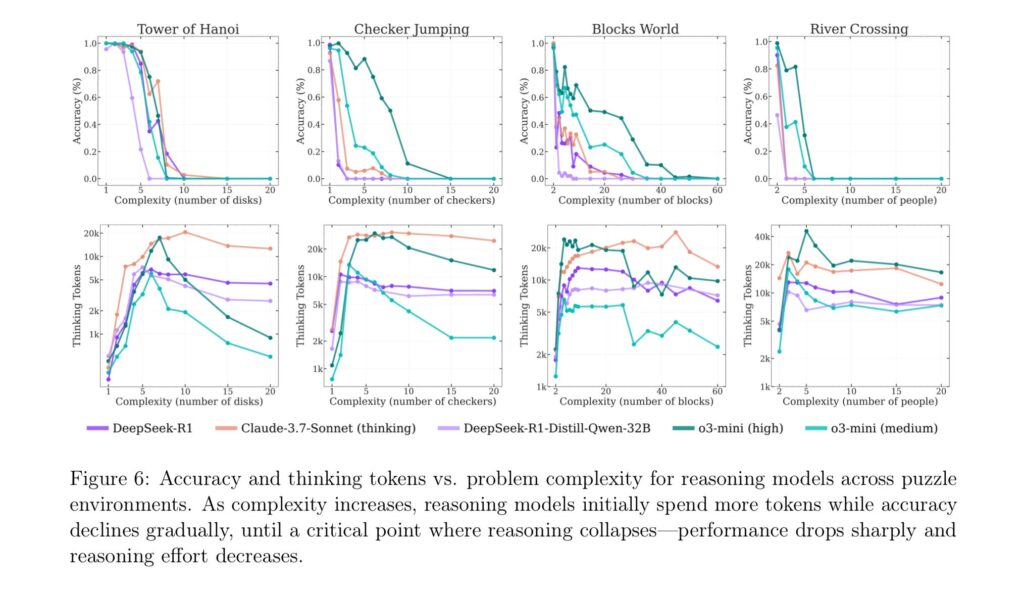
知名AI怀疑论者加里·马库斯(Gary Marcus)长期以来一直主张:神经网络在处理“分布外问题”(out-of-distribution generalization)时存在严重困难。在苹果公司最新发布的研究中,他称这些结果对大型语言模型(LLMs)来说是“相当毁灭性的”。 马库斯指出,即使研究人员为模型提供了解决汉诺塔问题(Tower of Hanoi)的明确算法,模型的表现依然没有改善。他写道:“LLMs 连汉诺塔都无法可靠解决,实在令人尴尬。”他还提到,早在1957年,AI先驱赫伯特·西蒙(Herb Simon)就已经成功解决了这个问题,而如今网络上也有大量现成的算法可供参考。 研究共同负责人伊曼·米尔扎德(Iman Mirzadeh)进一步指出,这一现象表明这些模型的“推理过程并不真正具备逻辑性和智能性”。 苹果团队的研究揭示了一个令人深思的现象:模拟推理模型(Simulated Reasoning Models, SR)在面对不同难度的任务时,其表现与“标准”语言模型(如 GPT-4o)存在显著差异。 在简单任务中(例如仅有几片圆盘的汉诺塔),标准模型反而表现更好,因为SR模型倾向于“过度思考”,生成冗长的推理链条,反而导致错误答案; 在中等难度任务中,SR模型的系统性推理方式展现出优势; 但在真正复杂的任务中(如10片以上圆盘的汉诺塔),两类模型都彻底失败,即使给予充足的时间和资源,也无法完成解题。 研究还提出了一个令人意外的现象,称为“反直觉的扩展极限(counterintuitive scaling limit)”:随着问题复杂度上升,SR模型一开始会增加“思考”内容(即生成更多推理token),但超过某个阈值后,反而减少推理努力,即使计算资源仍然充足。 更令人困惑的是,模型的失败方式并不一致。例如,Claude 3.7 Sonnet在汉诺塔中能连续完成100步正确操作,却在更简单的河流过渡问题中仅走了5步就失败。这表明模型的失败可能与任务类型有关,而不仅仅是计算能力或复杂度的问题。
Figure 6 from Apple's "The Illusion of Thinking" research paper. Credit: Apple 观点分歧正在浮现。尽管苹果的研究指出当前AI模型在复杂推理任务中存在根本性局限,但并非所有研究者都认同这一结论。 多伦多大学经济学家凯文·A·布莱恩(Kevin A. Bryan)在社交平台X上表示,这些局限可能并非源于模型本身的能力不足,而是出于训练策略的刻意限制。 他写道:“如果你让我在五分钟内解决一个需要我用一小时纸笔推演的问题,我大概率会给出一个近似解或启发式答案。这正是当前具备‘思考能力’的基础模型在强化学习(RL)中被训练去做的事。” 布莱恩进一步指出,虽然苹果研究强调模型在复杂任务中的“崩溃”,但实际上,行业内部的基准测试显示:只要允许模型使用更多推理token,其性能几乎在所有任务领域都会提升。然而,为了避免模型在简单问题上“过度思考”,实际部署时往往人为限制了推理长度和计算资源。 软件工程师肖恩·古德克(Sean Goedecke)在其博客中对苹果的研究提出了类似批评。他指出,当面对需要超过1000步操作的汉诺塔问题时,DeepSeek-R1模型“立即判断‘手动生成所有这些步骤是不可能的’,因为这需要跟踪上千次移动”。于是模型开始“兜圈子”试图寻找捷径,最终失败。古德克认为,这种行为更像是模型主动选择不尝试,而不是能力不足。 其他研究者也质疑:用逻辑谜题来评估大型语言模型(LLMs)是否合理。独立AI研究者西蒙·威利森(Simon Willison)在接受《Ars Technica》采访时表示,用汉诺塔来测试LLMs“本身就不是一个明智的应用方式”,无论是否涉及推理。他进一步指出,模型的失败可能只是因为上下文窗口(context window)限制,即模型可处理的文本长度不够,而非真正的推理能力缺陷。 威利森还认为,这篇论文之所以引发广泛关注,更多是因为“苹果质疑AI是否会思考”这个吸睛标题,而非其研究内容本身的深度。他将其称为“可能被夸大的研究”。 这些观点提醒我们,在评估AI推理能力时,测试方法本身的设计与假设同样值得反思。 苹果研究团队本身也在论文的“局限性”部分中提出了重要提醒:不要对研究结果过度外推。他们指出,所使用的逻辑谜题环境仅代表推理任务中的狭小一隅,并不能全面反映现实世界中多样化、知识密集型的推理问题。 此外,研究也承认,推理模型在“中等复杂度”任务中确实展现出性能提升,并且在某些现实应用中依然具有实用价值。这表明,尽管当前模型在高复杂度任务上存在明显瓶颈,但它们并非一无是处,而是在特定范围内仍具备可观的能力。 换句话说,这项研究更像是一面镜子,反映出当前AI推理模型的边界与潜力,而不是一纸“否定判决”。 影响仍在争议之中 这两项研究是否彻底摧毁了关于AI推理模型可信度的主张?未必如此。 更合理的解读可能是:这些研究表明,当前模拟推理模型(SR models)所依赖的“扩展上下文推理技巧”,并非通往通用智能(AGI)的可行路径。换句话说,若要实现更强大的推理能力,可能需要根本性的架构创新,而不仅仅是对现有方法的微调或堆叠。 正如西蒙·威利森(Simon Willison)所指出的,苹果这项研究在AI社区引发了极大的震动。生成式AI本身就是一个高度争议的话题,许多人在其通用性与智能性问题上持有极端立场:
这场争论不仅关乎模型性能,更触及了AI未来发展方向、评估标准与社会信任等深层议题。它提醒我们:在通往真正“会思考”的AI之路上,技术突破之外,还需要哲学、伦理与工程实践的共同演进。 |
|
 | |
|
 |
| 实用资讯 | |
|
|
| 一周点击热帖 | 更多>> |
| 一周回复热帖 |
| 历史上的今天:回复热帖 |
| 2024: | 初中物理附加题:复合弓上的滑轮有什么 | |
| 2024: | 美国一直是欧洲的工具,村霸是欧洲,美 | |
| 2023: | 中国出土的2400年前勾践剑vs.德国出土 | |
| 2023: | 皮教授有个问题,就是不太会看人,可能 | |
| 2022: | 一句话。 中国文化根本就没有给女性最 | |
| 2022: | 系统性女性欺辱又一例 | |
| 2021: | 中国没有毛主席就谁也玩不转 | |
| 2021: | 税收拯救资本主义世界 ZT+相关经济学原 | |
| 2020: | 据博顿回忆,老川赞老习是“中国300年 | |
| 2020: | 为什么会出现黑人命也是命的诉求?“法 | |
